chromVAR — TF Activity Scores#
Setup#
Download a MEME motif database file containing human transcription factor binding motifs from the Cis-BP resource, alongside the human genome in fasta format.
%%bash
[ -f data/cisBP_human.meme ] || wget -O data/cisBP_human.meme https://osf.io/download/uk6vn
[ -f data/GRCh38.fa ] || wget -O data/GRCh38.fa.gz https://ftp.ebi.ac.uk/pub/databases/gencode/Gencode_human/release_38/GRCh38.p13.genome.fa.gz
[ -f data/GRCh38.fa ] || gunzip -c data/GRCh38.fa.gz > data/GRCh38.fa
import gatac as ga
import scanpy as sc
import anndata as ad
import matplotlib.pyplot as plt
import numpy as np
sc .set_figure_params(dpi=100, frameon=False)
GENOME_FASTA = "data/GRCh38.fa"
MOTIF_FILE = "data/cisBP_human.meme"
peak_adata = ad.read_h5ad("data/pbmc_peaks.h5ad")
tile_adata = ad.read_h5ad("data/pbmc_spectral.h5ad")
print(peak_adata)
AnnData object with n_obs × n_vars = 5001 × 178350
obs: 'barcode', 'n_unique', 'tsse_score', 'duplicate_fraction', 'mito_fraction', 'leiden'
1. Compute peak biases#
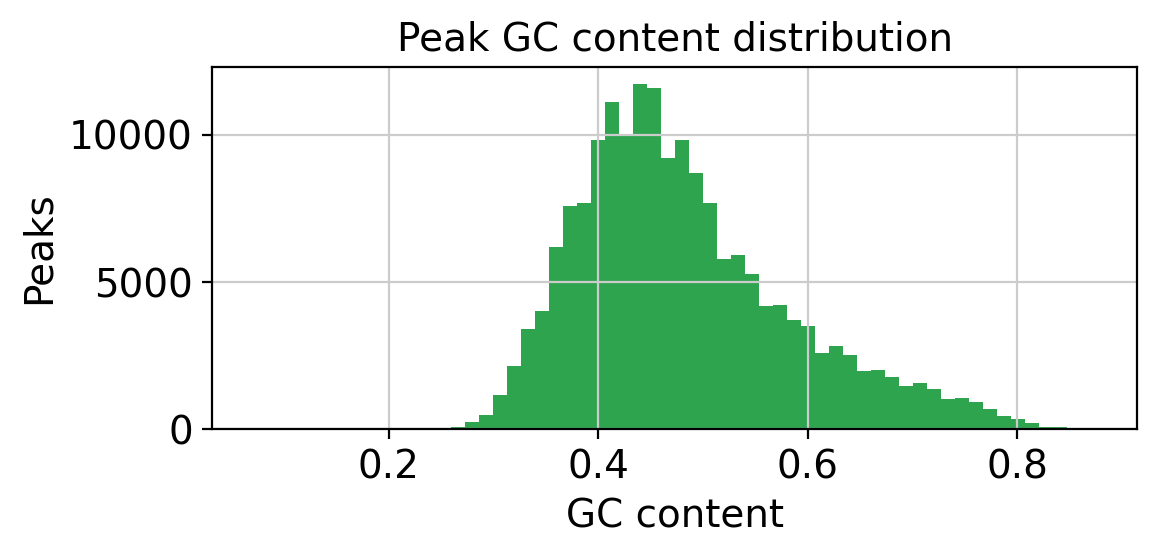
GC content is used to stratify peaks into bins for background sampling, ensuring that background peaks have similar GC content to the foreground.
import time
t0 = time.perf_counter()
ga.tl.compute_peak_bias(peak_adata, genome_fasta=GENOME_FASTA, add_gc_content=True)
print(f"Peak bias computed in {time.perf_counter() - t0:.1f}s")
fig, ax = plt.subplots(figsize=(6, 3))
ax.hist(peak_adata.var["gc_content"], bins=60, color="#2ea44f", edgecolor="none")
ax.set_xlabel("GC content")
ax.set_ylabel("Peaks")
ax.set_title("Peak GC content distribution")
plt.tight_layout()
plt.show()
15:33:50 - gatac.tl.chromvar - INFO - Computing peak biases from data/GRCh38.fa...
15:33:53 - gatac.tl.chromvar - INFO - Added 'gc_content' to adata.var
Peak bias computed in 2.3s
2. Sample background peaks#
ga.tl.sample_bg_peaks(peak_adata)
15:34:14 - gatac.tl.chromvar - INFO - Sampling background peaks using method 'knn'...
15:34:14 - gatac.tl.chromvar - INFO - Using cuML for k-NN background sampling...
15:34:15 - gatac.tl.chromvar - INFO - Sampled 50 background peaks for 178350 peaks. Stored in adata.varm['bg_peaks']
3. Run chromVAR#
The full chromVAR pipeline — motif scanning, expectation computation, and deviation scoring — runs entirely on GPU.
motifs = ga.tl.read_motifs(MOTIF_FILE, unique=True)
print(f"Loaded {len(motifs)} motifs")
ga.tl.scan_motifs(peak_adata, motifs, genome_fasta=GENOME_FASTA)
t0 = time.perf_counter()
ga.tl.compute_deviations(peak_adata)
print(f"chromVAR deviations computed in {time.perf_counter() - t0:.1f}s")
print(f"Deviation matrix: {peak_adata.obsm['chromvar'].shape}")
15:34:18 - gatac.tl.chromvar - INFO - Scanning 1165 motifs in 178350 peaks...
15:34:18 - gatac.tl.chromvar - INFO - Using 0-based coordinate system
15:34:18 - gatac.tl.chromvar - INFO - Fetching sequences from genome...
Loaded 1165 motifs
15:34:20 - gatac.tl.chromvar - INFO - Background from sequences: A=0.2589 C=0.2412 G=0.2411 T=0.2588
15:34:20 - gatac.tl.chromvar - INFO - Computing score thresholds...
15:34:24 - gatac.tl.chromvar - INFO - Scanning motifs on GPU in 4 batch(es) of 50000 peaks...
15:38:43 - gatac.tl.chromvar - INFO - Found 16437627 motif matches (7.91% density). Stored in adata.varm['motif_match']
15:38:43 - gatac.tl.chromvar - INFO - Computing chromVAR deviations on GPU...
15:38:43 - gatac.tl.chromvar - INFO - Computing expectation reads per cell and peak...
15:39:13 - gatac.tl.chromvar - INFO - Computed chromVAR deviations: (5001, 1165). Stored in adata.obsm['chromvar']
chromVAR deviations computed in 29.4s
Deviation matrix: (5001, 1165)
Another way to run the full chromvar pipeline in one command is to use:
ga.tl.chromvar(peak_adata,genome_fasta=GENOME_FASTA,motifs_path=MOTIF_FILE)
This runs all steps 1 to 3.
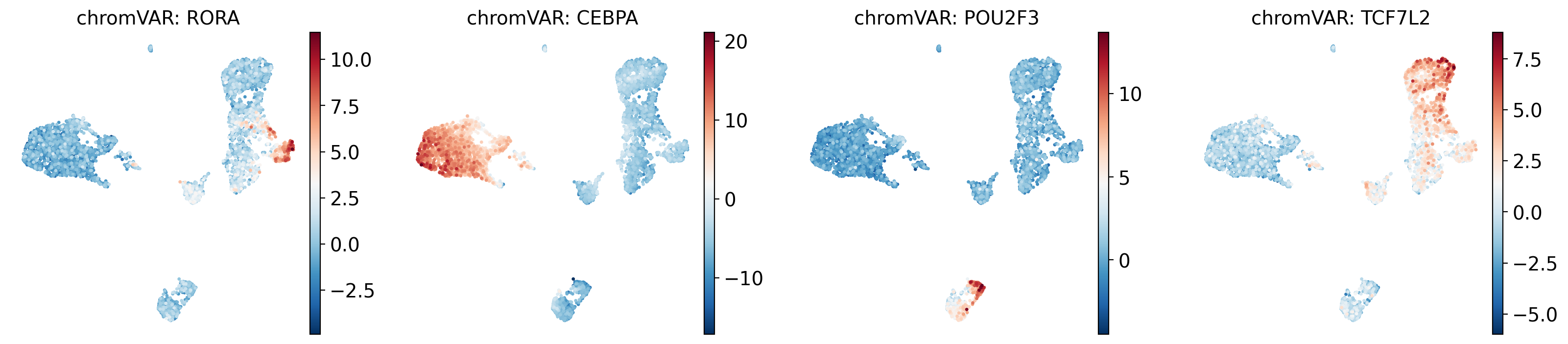
4. Visualize TF activity on UMAP#
# Transfer UMAP from tile_adata
peak_adata.obsm["X_umap"] = tile_adata.obsm["X_umap"]
# Build a sub-AnnData with chromVAR scores for Scanpy plotting
import anndata as ad
import pandas as pd
import scipy.sparse as sp
motif_names = peak_adata.obsm['chromvar'].columns.tolist()
cv_adata = ad.AnnData(
X=sp.csr_matrix(peak_adata.obsm["chromvar"]),
obs=peak_adata.obs,
)
cv_adata.var_names = motif_names
cv_adata.obsm["X_umap"] = peak_adata.obsm["X_umap"]
# Plot top variable TFs
top_tfs = ["RORA", "CEBPA", "POU2F3", "TCF7L2"]
available = [tf for tf in top_tfs if tf in cv_adata.var_names]
if available:
sc.pl.umap(cv_adata, color=available, ncols=4, cmap="RdBu_r",
title=[f"chromVAR: {tf}" for tf in available])
Next steps#
05 – GSEA: gene-set enrichment on ranked peaks